4.1.6. Unix way - parse_gps¶
Let’s take a look at our software architecture diagram again:
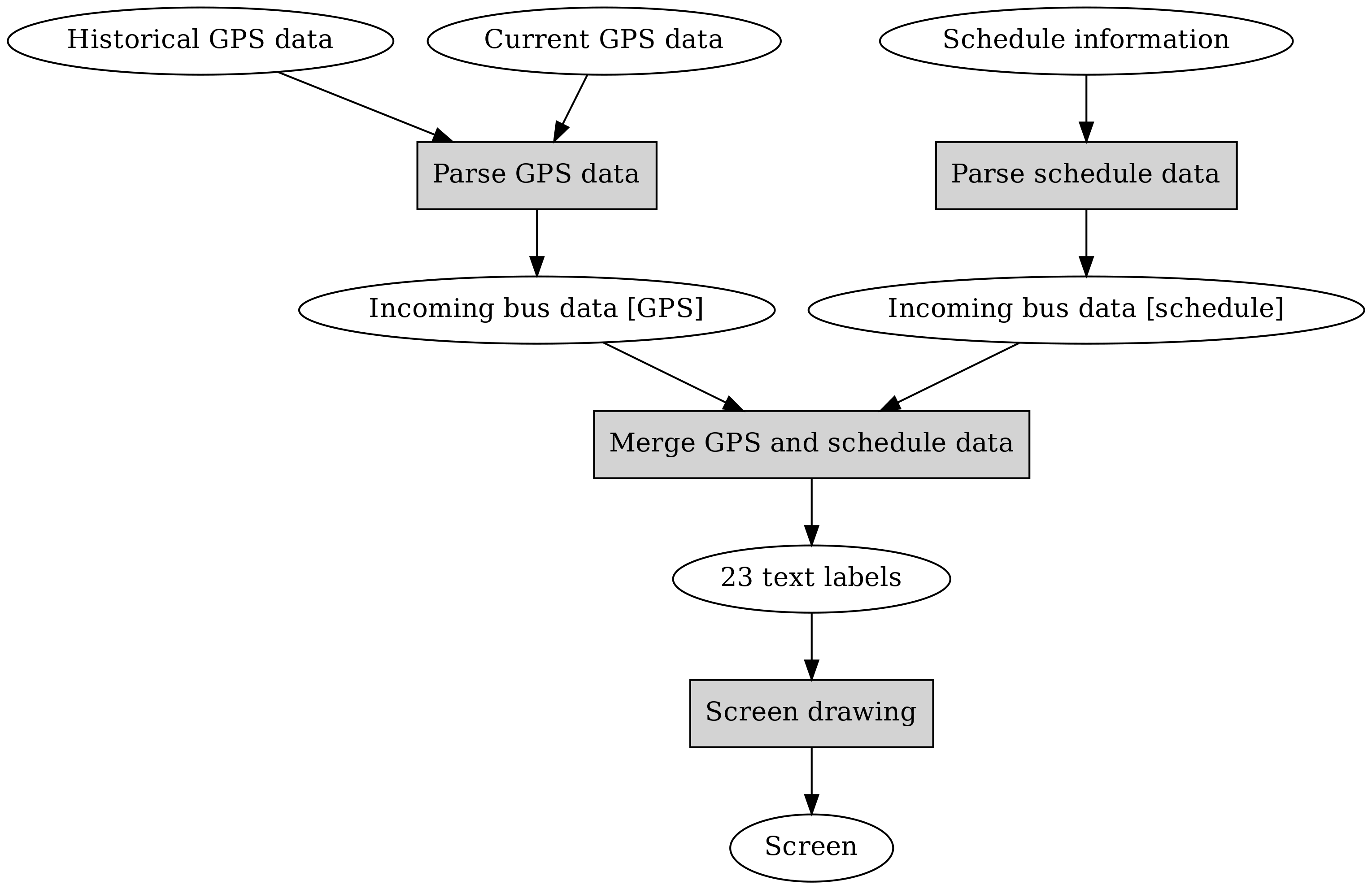
Before we implemented the schedule data parsing and screen drawing boxes. Let’s implement the GPS data parsing next.
Parsing the GPS data takes both historical as well as current GPS data as input and outputs a description of buses expected to arrive soon in the same format as sched. The requirements specification gives some input as to how exactly the input format should look like, for both historical and current GPS data:
“[…] Each line has four numbers separated by spaces. The first integer identifies the route. The second is the time it took for the bus to reach the bus stop at the time the data was collected. The third and fourth are the position coordinates relative to the bus stop. They’ve been normalised such that the unit is in meters as opposed to degrees.
[…] Each line has at least five numbers separated by spaces. […] The first number identifies the route. The second identifies the start number as is used in the schedule file. The third and fourth provide the relative position of the bus to the bus stop as is used in the historical GPS file. The fifth identifies whether the bus has already passed the bus stop.”
The specification furthermore explains the desired logic for predicting the bus arrival time:
“The time to reach the bus stop is assumed to be the average time of all the points in the historical data within 100 meters of the current bus position for the route of the bus.”
How would you go about implementing this program? Have a think.
As with sched, let’s imagine some testing data, sketch the plan for the software top down and implement it bottom up, i.e. the most detailed part first.
For the historical data, we can e.g. put together just six data points, such that we have two routes with three data points each, at different locations. For example:
3 5.5 100.0 100.0 3 6.5 150.0 150.0 3 9.5 500.0 500.0 6 5.5 100.0 100.0 6 6.5 150.0 150.0 6 9.5 500.0 500.0
Here, we have mock-up data for bus routes 3 and 6; three data points each. The first column is the bus route number. The last two columns are coordinates indicating the bus position relative to the bus stop (bus stop being at 0, 0). The second column indicates the time, in minutes, it took for the bus to reach our bus stop. As you can see, we’ve seen buses that are 500 meters out in both X any Y directions to take nine and a half minutes to reach our stop while buses nearer have required less time.
Let’s mock up some relevant current GPS data:
3 3 120.0 120.0 0 6 3 475.0 475.0 0 5 3 130.0 130.0 0 3 2 320.0 320.0 2
Here, we have information about four buses:
- Bus with start number 3 from route 3 is at location (120, 120) and has not yet passed the bus stop. We’d expect our program to see that there are two historical data points which can be used for this bus, as those two data points are for route 3 and within 100 meters of the current location. Considering that according to the requirements, the average time from historical data from data points within 100 meters should be used for estimates, how many minutes should our program estimate this bus to take before arriving at the bus stop?
- Bus with start number 3 from route 6 is at location (125, 125). We have one historical data point that our program is able to use to predict the arrival time.
- Bus from route 5 is included but we have no historical data for this bus.
- Bus with start number 2 from route 3 has already passed the stop.
Exercise: Write down what the expected output for the program would be for this input data. The program will receive some timestamp (hour and minute) as an input parameter; pick some numbers. Check that the output data format matches with the data from sched.
Now, how would we implement software to perform this operation? Again, let’s break this down to sub-tasks:
- We need to parse the command line arguments and read in the input data
- We need to loop through the current bus information
- For each current bus, we need to decide what the output should be
- For a bus that has passed we simply output the fact that the bus has passed
- We should output the estimated arrival time whenever we have the historical data to be able to calculate the estimation
- For other buses we won’t be able to output anything
- We finally output the results in the required format
Exercise: Put together the skeleton for the program: parse the command line arguments, open the files, read in the information from the files to lists. Feel free to either store a data point (a row in either file) either to a tuple or using a class and member variables. You can convert a string to a floating point value by using e.g. “f = float(s)”. You can remove all whitespace (line breaks, spaces etc.) from a string by using the “strip” string member function, e.g. s.strip(). Your program doesn’t need to output anything yet.
Now that we have the skeleton in place, we can try to implement the core logic. There are a couple of primitives that our core logic requires, namely calculating an average of a list of numbers and calculating the distance between two coordinates; it might be interesting to implement these first.
Exercise: Implement and test a function to calculate the average of numbers in a list. You can use the built-in function “sum” to sum all the values in a list. Note that you probably want to cast the denominator to a floating point number to ensure the result is also a floating point number.
Exercise: Implement and test a function to calculate the distance between two coordinates. Use the Pythagorean theorem for this: distance = math.sqrt((x_diff ** 2) + (y_diff ** 2)). You need to import math to have access to the sqrt function.
For the most complex part of deciding what the output should be, the pseudocode could look something like this:
for bus in current_gps_data:
if bus.passed:
# don't try to predict the arrival time but note that
# we need to include this bus in the output
else:
# find historical data points for this route
historical_data_points =
[data_point for data_point in historical_data if
data_point.route_number == bus.route_number]
# only include data points that are within 100 meters
# of current position
close_historical_data_points =
[point for point in historical_data_points if
distance(bus.position, point.position) < 100.0]
bus.estimated_time_from_now = calculate_average(close_historical_data_points)
In other words, we need to find the relevant historical data points (matching route number and close enough to the current bus location), and then calculate the average arrival time based on them. Once we have this information we can print it out.
It seems like we’re starting to have all the pieces so we can put our program together.
Exercise: Implement the rest of your program. Test it with the mock-up data first. If that passes, see what output you get for the larger test files that were provided.